42dot에서는 자율주행기술 개발을 위해 머신러닝 기술을 적극적으로 활용하고 있습니다. 머신러닝 개발의 경우 고도의 알고리즘, 대량의 데이터 그리고 복잡한 컴퓨팅 연산이 필요하고 이를 수행하기 위해서는 software 및 hardware의 효율적인 지원이 필요합니다. 이를 위에 42dot에서는 다양한 기술을 이용하여 machine learning&data platform을 개발하여 운영하고 있으며, 지금도 42dot의 머신러닝 개발자들이 이를 활용하여 효과적인 개발 업무를 진행하고 있습니다.
.jpg&blockId=f5ed1162-3bf3-43b4-b92b-0e9e57f26774)
Data Pipeline
머신러닝 개발에 있어서 데이터는 매우 중요합니다. 머신러닝 모델의 성능을 높이기 위해서는 많은 양의 데이터가 필요하고, 또한 많은 양의 데이터 중에서 성능 향상에 도움이 될 가능성이 높은 데이터를 골라내는 작업(data curation) 역시 중요합니다. 이러한 데이터 준비 작업의 경우 복잡성이 높고 시간이 많이 걸리는 작업입니다. 42dot에서는 자동화된 data pipeline을 개발 운영하고 있으며 머신러닝 개발자들이 데이터 관련 작업을 빠르고 효율적으로 수행할 수 있도록 지원합니다.
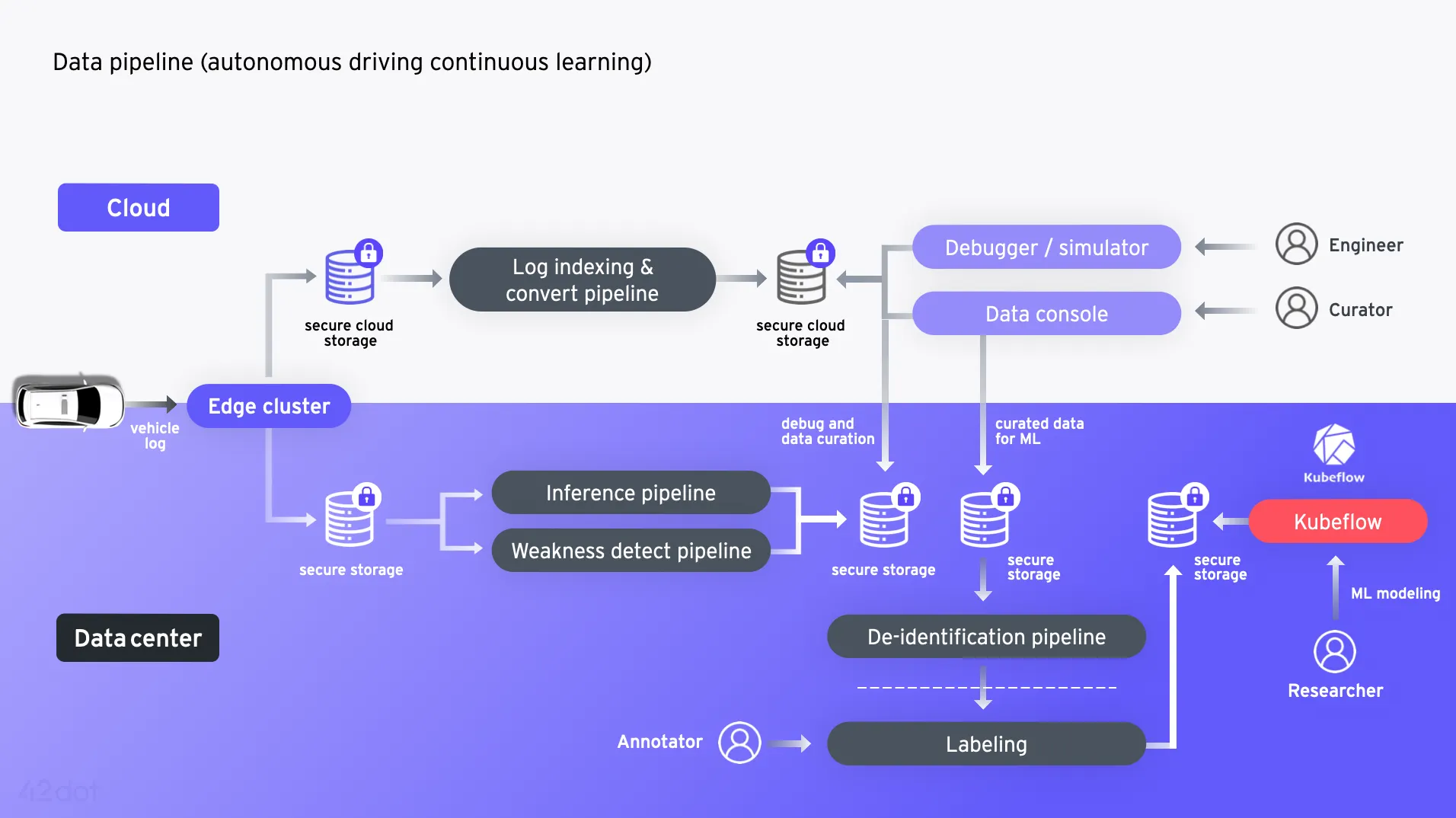
Data pipeline은 다음과 같이 동작합니다.
1) 차량을 통해 도로에서 수집된 데이터는 각 사이트의 엣지 클러스터를 통해 클라우드와 데이터 센터로 전송됩니다.
2) 클라우드로 전송된 데이터는 검색을 위한 변환과 인덱싱 작업을 거쳐 데이터베이스에 저장됩니다.
3) 데이터 센터로 전송된 데이터는 GPU 서버를 이용하여 inference 작업을 거쳐 태그를 생성하고 data curation 작업을 위해 weakness detection pipeline을 거쳐 데이터베이스에 저장됩니다.
4) 저장된 데이터는 디버깅과 re-simulation을 통해 개발 과정에 사용되거나, data console을 통해 data curation 작업을 수행합니다.
5) 수집 데이터의 안전한 사용을 위한 개인정보 암호화, 비식별화 등의 보호 조치를 추가로 수행합니다.
6) 레이블링을 마친 데이터는 GPU 클러스터에 연결된 shared storage에 저장됩니다. 머신러닝 개발자는 Kubeflow 기반 ML workspace를 통해 접근하여 개발 작업을 진행합니다.
ML Workspace
머신러닝 학습에는 많은 연산이 필요하고 일반적으로 GPU 서버를 사용하여 진행합니다. 머신러닝 개발팀의 경우 여러 대의 GPU 서버를 사용하여 개발하게 되는데, GPU 서버를 얼마나 효율적 사용하는가 또한 중요합니다. 동일한 자원일 경우 가능하면 모델 학습을 여러 사이클 돌릴수록 더 빠른 개발이 가능하기 때문입니다.
개발을 위해 필요한 각종 라이브러리 설치 등 개발 환경을 갖추는 작업 또한 필요한데요, 이러한 요구사항을 위해 42dot에서는 Kubeflow를 기반으로 한 ML workspace를 제공합니다.
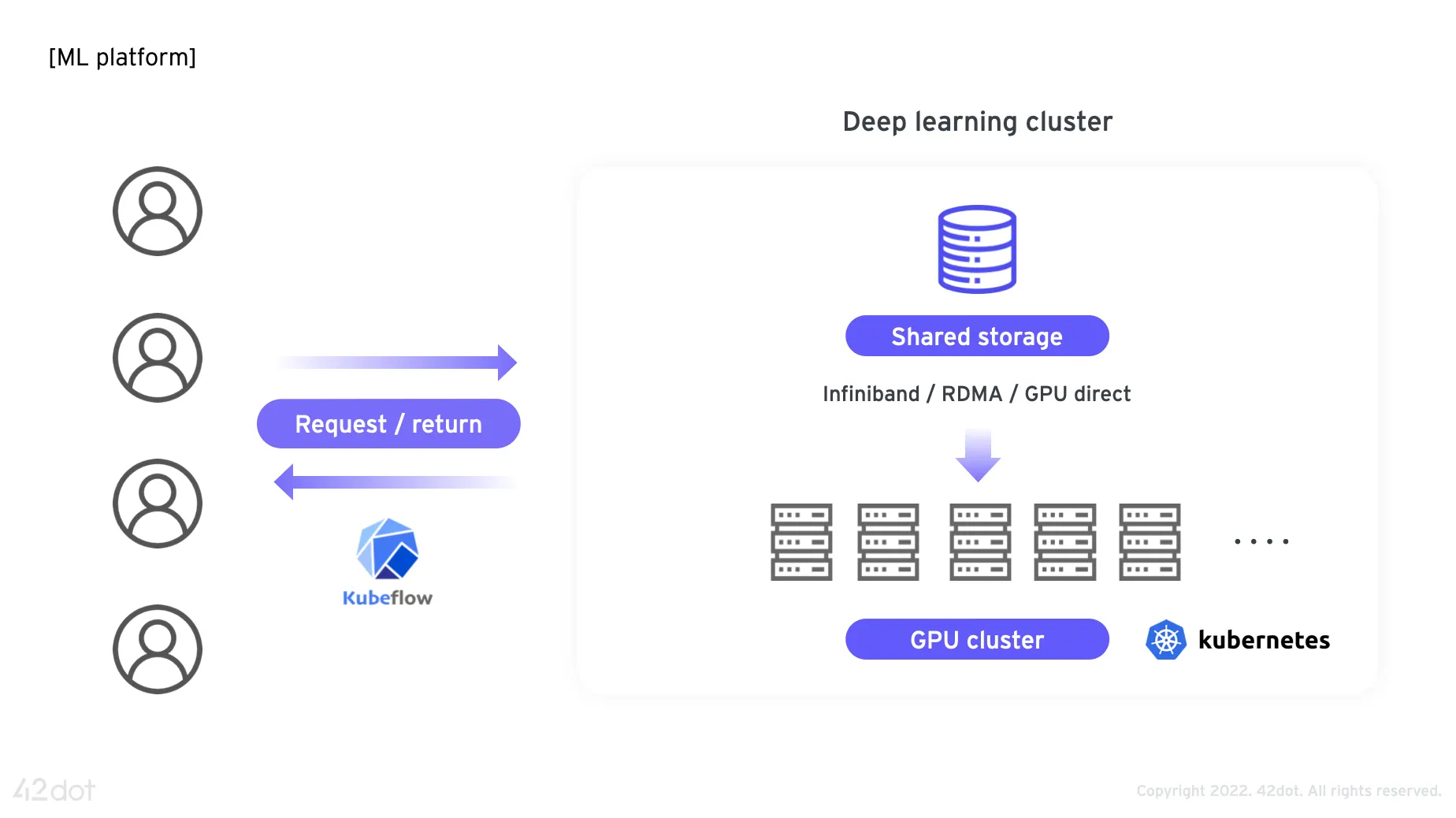
GPU 클러스터의 경우 여러 대의 GPU 서버를 Kubernetes 클러스터로 구성하고, 여기에 shared storage를 고속의 네트워크로 연결하여 직접 접근 가능하도록 구성하였습니다. 이렇게 구성된 클러스터에 Kubeflow 기반 시스템을 구축하여 개발자들이 쉽게 접근 가능하도록 지원하고 있습니다. 개발자들은 원하는 스펙(CPU, memory, GPU …)의 가상 서버 인스턴스를 요청하여 사용할 수 있으며 사용을 마치고 나서는 다시 반납할 수 있습니다.

할당받은 가상 서버 인스턴스의 경우 브라우저를 통해 접근 가능하며, 머신러닝 개발에 필요한 대부분의 기능을 제공하고 있어 편리하게 사용 가능합니다.
ML Pipeline
머신러닝 개발 과정은 일반적으로 학습, 평가, 모델 변환, 통합 테스트, 배포 등의 과정을 반복적으로 수행하게 됩니다. 개발 속도를 높이기 위해서는 반복적으로 수행하는 작업을 최대한 자동화하여 개발자들이 개발 자체에 집중할 수 있도록 하는 것이 중요한데요, 저희 42dot에서는 다양한 기술을 활용하여 자동화를 지원하고 있습니다.

첫 번째로 MLFlow를 활용하여 training tracking과 model registry를 지원하고 있습니다. 모든 학습 과정은 클라우드에 설치된 MLFlow에 자동으로 기록되고 학습의 결과물은 model registry에 저장됩니다. 이를 통해 권한이 있는 사용자는 누구나 어떤 데이터와 어떤 파라미터를 사용한 모델이 가장 좋은 결과를 보여주는지를 손쉽게 검색 가능하며 테스트 및 배포 과정에서도 학습 결과물을 API를 통해 쉽게 접근 가능하도록 지원하고 있습니다.
두 번째로 ML pipeline입니다. model registry에 학습 결과물이 등록되면 평가, 모델 변환, 테스트를 위한 pipeline이 자동으로 수행됩니다. Kubeflow pipeline을 이용하여 수십여 개의 pipeline이 동작 중이며 하루에도 수백 번 이상 자동으로 수행되어 자율주행 기술 개발을 가속시키고 있습니다.
・ ・ ・
지금까지 42dot 머신러닝 개발팀에서 사용하고 있는 ML data platform에 대해 소개 드렸습니다. 자율주행 기술 개발의 기나긴 여정을 조금이라도 앞당길 수 있도록 ML data platform 또한 지속적인 개발과 개선을 진행할 예정입니다.

양원렬 | Data & ML (Tech Lead)
자율주행 기술 성능 향상을 위한 Machine Learning & Data platform 개발을 담당하고 있습니다.

.png&w=750&q=75)
.png&w=750&q=75)
.png&w=750&q=75)
.png&w=750&q=75)
.png&w=750&q=75)
.png&w=750&q=75)
.png&w=750&q=75)